AI
Deign
I built a UX research agent that will tell you when it's wrong
Let me say this: I love doing research and understanding users. I could talk to them for hours, I could read their feedback like I'd read my yearly horoscope. However, somewhere around the fortieth open-ended survey response, your brain quietly gives up.
You stop reading and start skimming. You start nodding along to the themes you already expected to find (hi, confirmation bias, didn't see you there). And there's this little voice that goes: just paste the whole thing into an AI, ask for the top five pain points, nobody will know.
I know that voice. I built a thing partly to argue with it.
The easy, slightly evil version
I used ChatGPT at the end of 2025 to summarise a survey and boy, it hallucinated more than a middle-aged white woman looking for herself on ayahuasca.
Here's what most "AI summarises your feedback" tools do: they read your messy pile of user voice, and they hand you back something clean, confident, and maybe somewhat wrong. A tidy narrative. Five neat pain points. Quotes that sound real but that nobody actually said. Opinions wearing a lab coat, pretending to be findings.
For literally anything else, "confident and mostly right" is fine. For research, it's worse than useless because the entire job of research is to not fool yourself. An AI that fabricates a plausible insight isn't saving you time. It's laundering your assumptions back to you with a citation you didn't check.
So I didn't want to build a thing that sounds smart. I wanted to build a thing that knows what it doesn't know.
The whole idea, in one line
AI is a first pass, not a verdict.
That's it. You might think "oh, no shit Sherlock", but I think it's worth saying out loud, because every decision I made afterwards is just me being annoyingly consistent about that one sentence.
The decisions (a.k.a. me arguing with a robot for a few hours)
A few of these were obvious. A few of them I had to think about way harder than I expected.
No fixed buckets. My first instinct was to give it tidy categories: Usability, Performance, etc. Classic. Then I realised I'd basically be telling it the answer before it read the data. A pain point that's really about trust gets shoved into "Usability" because that's the closest box, and now my framework is quietly editing reality to fit. Nope. The themes have to come out of the data, not get stamped onto it.
Severity isn't a popularity contest. Forty people saying "the font's a bit small" should not outrank three people saying "the app deleted my work." So severity is impact × reach, not just a tally. The rare-but-catastrophic stuff still gets to scream.
Every claim drags a real quote behind it. No quote, no finding. And the quotes are copied exactly. no helpful little paraphrasing, no "tidying up" what someone said. A quote is evidence. The finding is my interpretation of the evidence. Those are different jobs and the tool isn't allowed to blur them.
It stays in its lane, no jumping to solutions. The data tells me there's a problem. It does not tell me my fix will work. So the agent never hands you "so just do X" dressed up as a finding. That'd be smuggling a design decision in wearing a research badge, and it quietly kills the divergent thinking that's supposed to happen next. Findings stay findings. Opportunities get framed as "how might we" questions. And any actual suggestion gets fenced off in a clearly-labelled "this goes beyond the data, it's yours to test" zone, with reasoning that leans on real UX principles rather than "well, a guy said so."
Knowing when to stop at the problem and hand the leap to a human is the whole game. Funny how restraint is the hard part.
It second-guesses itself before it talks. Before writing anything, it does a self-critique pass "did I miss a theme, is any quote thin, am I about to assert something I can't back?" and then it does the thing I'm weirdly proud of:
It flags when the human needs to take a deeper look. Every spot where the tool is uncertain gets a little ⚠️ Review button, right where the doubt lives, that opens up why. "This is one person, not a pattern." "All these complaints are from new users — could be a real gap, could just be unfamiliarity." "I split these two themes by judgment; you might disagree." It's not burying the uncertainty at the bottom in a section nobody reads. It's pointing at its own soft spots and going look here first.
That's the whole personality, honestly. It's a very capable, very fast assistant that constantly says "…but check me on this."
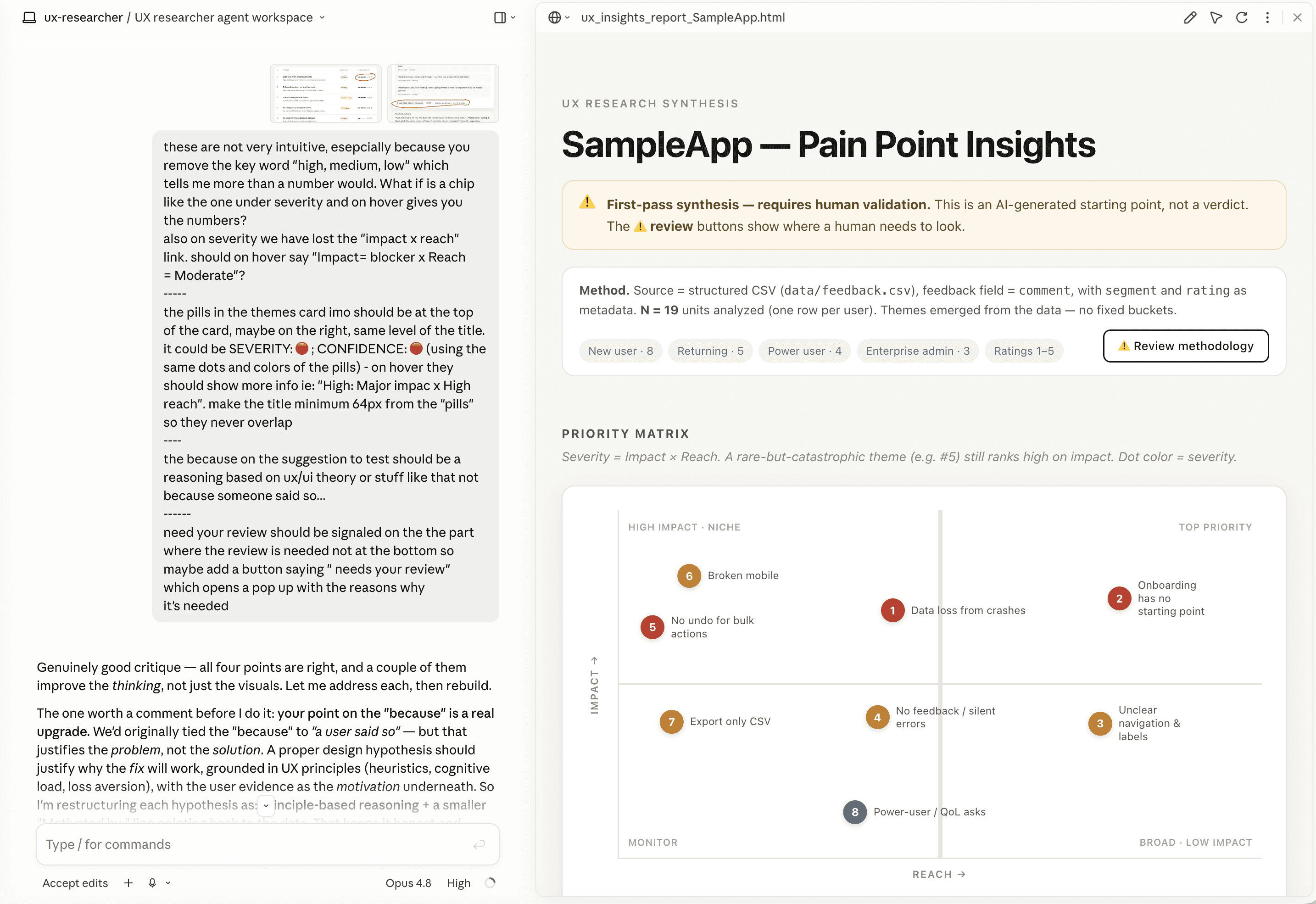
It also doesn't look like a robot wrote it
Because I'm a designer and I physically cannot help myself, the output isn't a wall of grey text. Every run spits out a proper report: colour-coded severity, confidence you can actually read, an impact-vs-reach matrix so the priorities are visible, quotes in context, the review flags built in. It looks like a deliverable, not a chat log. (The boring markdown version exists too, for the people who live in their text editors. I see you. I am also you.)
The bit that makes it more than my little toy
Here's where it stops being "Fed's weekend project" and starts being kind of a point.
Drop this into a team and suddenly everyone has a researcher-quality first pass. The PM drowning in tickets. The support lead who's never run a study in their life. The tiny startup with no researcher at all, currently running on vibes and the loudest customer in the room.
And because the guardrails are baked in (no invented quotes, honest confidence, "check me here" flags everywhere) the non-researchers don't get handed false confidence. They get handed something that's upfront about its own limits. Meanwhile the actual researchers get their time back for the part only a human can do: validating, going deeper, and arguing with the agent's blind spots (which, conveniently, it has already circled for them).
It doesn't replace the researcher. It scales research capacity without watering down research rigour. That's the line most "AI for research" tools faceplant straight over.
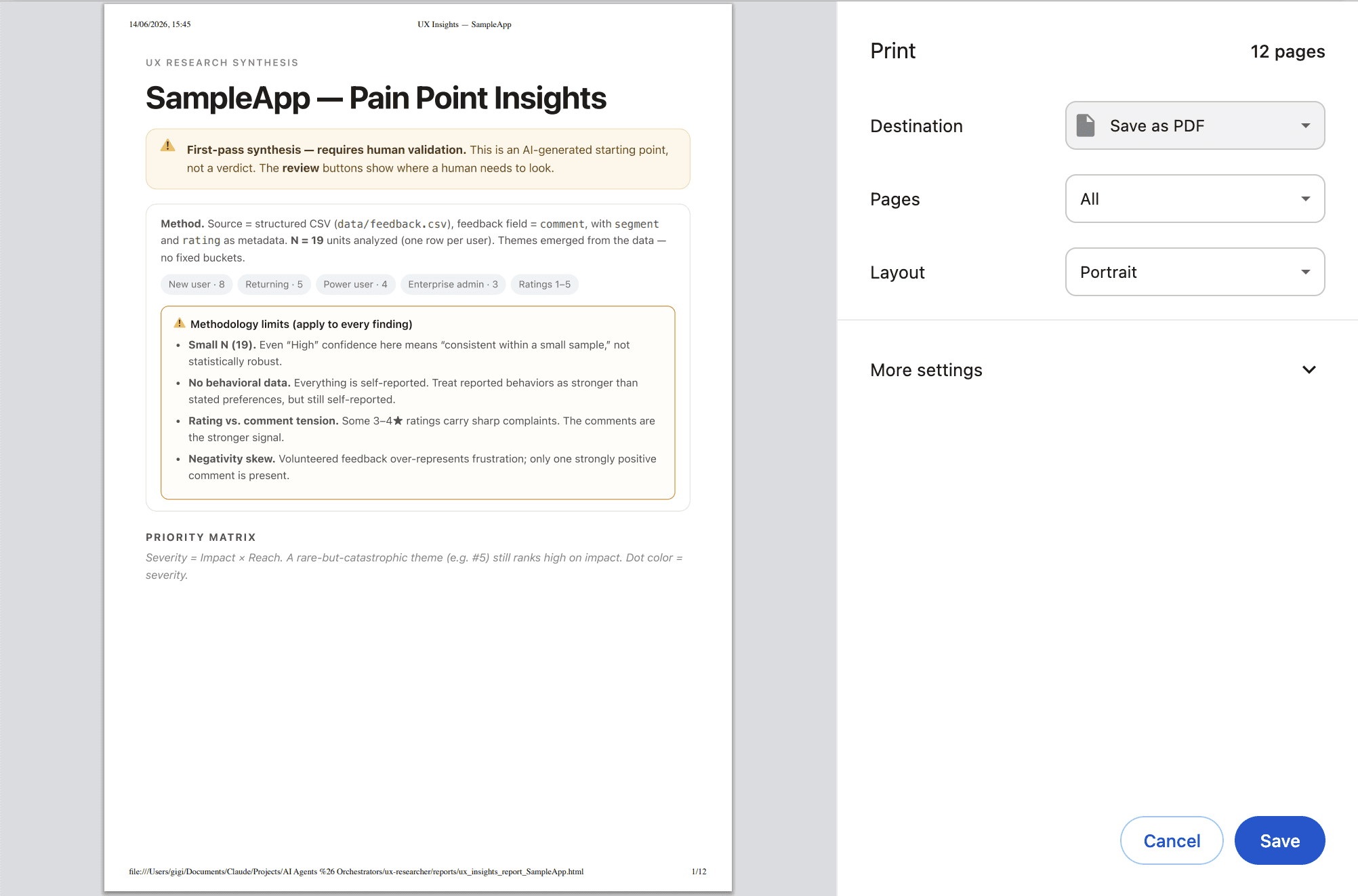
The thing I actually want to build next
Here's where my brain wandered after all this, and honestly it's a bigger deal than the tool itself.
One tidy report is lovely. But research has a nasty habit of evaporating. Someone runs a study, writes it up, drops it in a Slack channel, and four months later someone else runs the exact same study because they had no idea it existed. The knowledge doesn't pile up. It just quietly leaks out the bottom.
So the real dream isn't "synthesise one survey." It's: take every scrap of research everyone on the team has ever done and pour it into one place you can actually talk to. Not a graveyard folder of 40 PDFs nobody opens, but a shared brain you can ask:
"What do we know about onboarding?" "Has anyone ever heard users complain about exports?" "How strong is our evidence that pricing is the problem?"
And here's the sneaky payoff: all that fussiness about consistent format, real quotes, confidence scores, where-did-this-even-come-from, that was never pedantry. You can't pool a pile of freeform documents. You can pool a pile of structured findings. The rigour was secretly the thing that makes the shared brain possible later.
The feature I'm most excited about, though, is the one that says "we actually don't know that". Most repositories tell you what exists. One that can point at the holes tells you what to go find out next. That's the difference between a filing cabinet and a map.
That's a whole other build (stay tuned?!). But it's the same stubborn idea, just bigger: let the machine hold the library, keep the judgment human.
So, am I delulu about AI replacing me?
What I actually believe, after a few hours of arguing with this agent, is narrower and a lot more useful: the machine is genuinely brilliant at the first 80%: the reading, the sorting, the pattern-spotting that melts your brain by response number forty. And it is genuinely bad at the last 20%: the context, the judgment, the should we even be solving this - which, surprise, is the part that was always actually our job.
The trick isn't using AI or not using AI. It's knowing exactly where the handoff is. Where the evidence ends and the decision begins. That line is ours to hold.
I just built a tool that's weirdly insistent on reminding everyone where it is.